Back
Work AI
What is an Information Retrieval System? Meaning, Components, Types, and Examples

Tushar Dublish

Ever searched for something online and found exactly what you needed in seconds? Or maybe you typed a question into a search box, hit Enter, and bam! The relevant answers appeared as if by magic. Behind that seemingly simple action lies a powerful concept that quietly runs the modern digital world.
That concept is an information retrieval system.
So, what is information retrieval system, really? Is it just a fancy term for search engines? Or is it something deeper, something more foundational? Short answer: it’s much deeper. Longer answer? Well, you’re in the right place.
This article unpacks the information retrieval system meaning in plain, simple English. No jargon overload. No robotic tone. Just a clear, human explanation of how information is stored, searched, ranked, and delivered. All at the exact moment someone needs it.
By the end, you’ll understand not only what an information retrieval system is, but why it matters more today than ever before.
What is Information Retrieval System? Explained Simply
At its core, an information retrieval system (often called an IR system) is a system designed to find relevant information from a large collection of data based on a user’s query.
In simple words:
An information retrieval system helps users find the right information, from the right place, at the right time.
Unlike traditional databases, which return exact matches, IR systems work with relevance, probability, and context. They don’t just ask, “Does this data exist?” They ask, “Is this data useful right now?”
To understand what is information retrieval system in a practical sense, think of:
Search engines like Google
Library catalog systems
Email search tools
Recommendation engines
Document management platforms
AI-powered chat systems
All of them rely on information retrieval at some level.
In many modern enterprises, this goes far beyond public search engines. Popular enterprise search platforms like Action Sync AI, for example, apply information retrieval across workplace tools to help teams instantly find decisions, documents, conversations, and context spread across apps like Slack, Notion, Jira, Google Drive, and more.
Information Retrieval System Meaning in Simple Terms
Let’s slow it down a bit and look at this idea from a more human angle.
The information retrieval system meaning can be broken into three simple ideas. Each one sounds ordinary on its own, but together, they form something surprisingly powerful.
Information
Data that has meaning. This includes text, images, audio, video, and even mixed formats. On its own, information is just raw material waiting to be understood.Retrieval
The act of finding and fetching that information when it’s actually needed. Not later. Not buried under noise. Right at the moment of intent.System
A structured process involving software, rules, and algorithms that work together behind the scenes to make retrieval fast, reliable, and scalable.
Put together, the definition becomes clearer:
An information retrieval system is a structured way to search, filter, and rank information so users can retrieve what they need efficiently, even from massive collections of data.
What makes it special isn’t storage. Storage is easy and cheap.
What makes it special is selection. It is the ability to separate what matters from what doesn’t, based on context and need.
This is exactly where modern enterprise information retrieval systems stand apart. Tools like Action Sync are built not just to retrieve documents, but to understand work context: what matters to a specific team, role, or moment, etc. So the system surfaces insight, not just files.
Anyone can store data. Only a good IR system can decide what deserves attention and what can safely be ignored.

Why Information Retrieval Systems Exist?
Here’s the uncomfortable truth: humans are drowning in information.
Every single day, we create and consume more data than any generation before us. It comes from every direction, often faster than we can process or even notice.
Every day, we generate:
Millions of articles across news sites, blogs, and research platforms
Billions of messages through emails, chats, comments, and social media
Endless videos, logs, images, and digital records stored across devices and clouds
Without information retrieval systems, all this data would blur into noise. Useless. Overwhelming. Important insights would stay buried, while irrelevant details would float to the surface. Finding anything meaningful would feel like searching for a needle in a constantly expanding haystack.
IR systems exist to bring order to this mess. They help:
Reduce information overload by filtering out what doesn’t matter
Save time and effort by surfacing relevant results quickly
Improve decision-making by delivering reliable, timely information
Enable discovery of hidden knowledge that might otherwise remain unseen
In short, they don’t just organize data. They turn chaos into clarity, confusion into confidence, and raw information into something people can actually use.
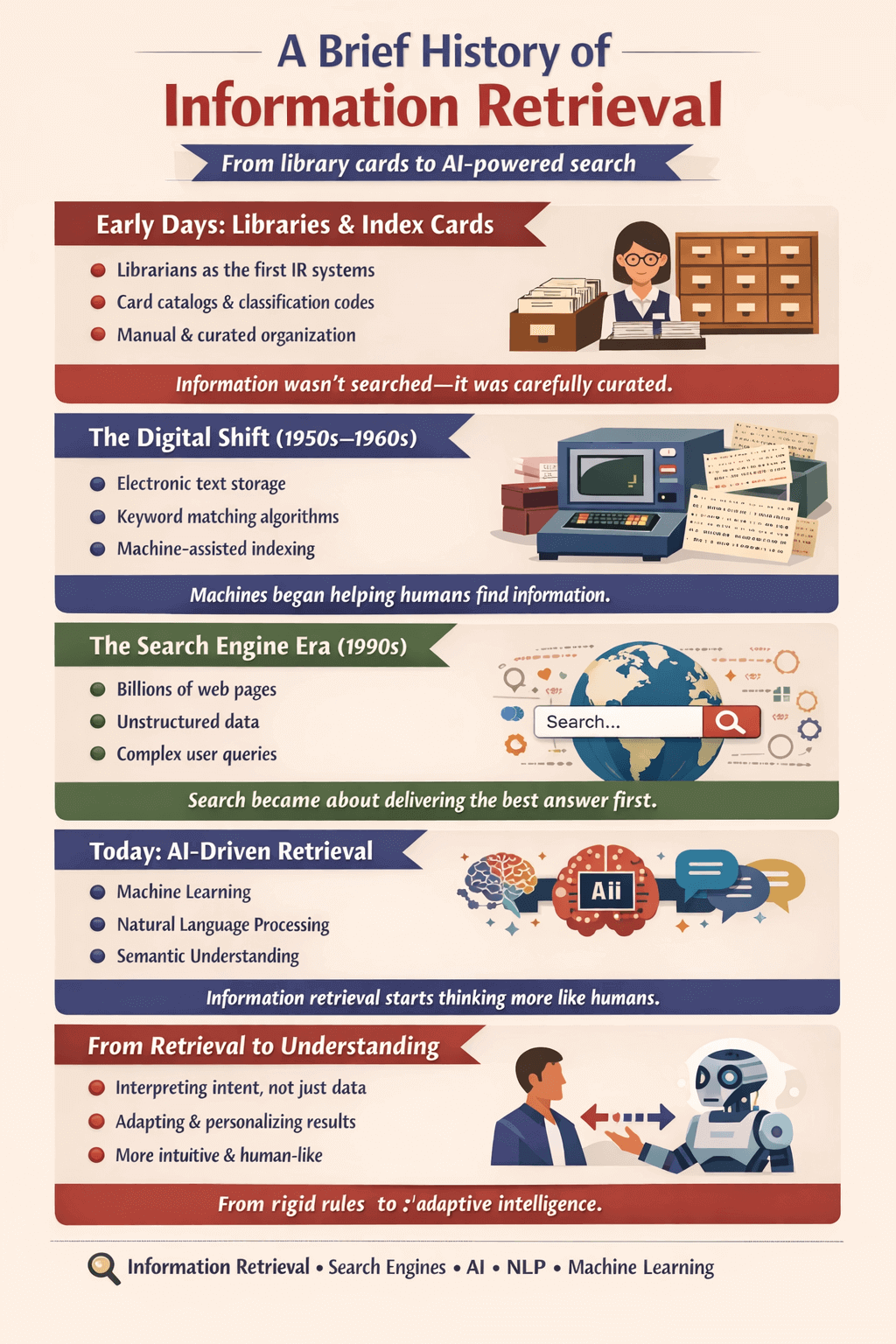
A Brief History of Information Retrieval
Information retrieval didn’t start with Google. Far from it. The idea of finding the right piece of information from a large collection has existed for centuries, long before computers, the internet, or search boxes ever appeared.
Early Days: Libraries and Index Cards
Before computers, librarians were the original IR systems. Card catalogs, classification codes, and subject indexing were manual retrieval mechanisms designed to help people locate books and documents efficiently. Librarians didn’t just store information; they organized it thoughtfully so users could discover relevant material without scanning every shelf.
These early systems relied heavily on human judgment. Categories were carefully chosen, subjects were mapped, and cross-references were created by hand. Slow by today’s standards, yes — but surprisingly effective for their time.
The Digital Shift
In the 1950s and 1960s, researchers began exploring automated document retrieval as computers entered academic and government institutions. Early experiments focused on storing text electronically and using simple algorithms to match keywords.
As computers evolved, so did indexing techniques. Storage became cheaper, processing became faster, and retrieval moved from manual effort to machine-assisted workflows. This period laid the technical foundation for everything that followed.
The Search Engine Era
The 1990s brought web search engines, and everything changed almost overnight. Suddenly, IR systems had to handle:
Massive scale, with millions and then billions of documents
Unstructured data that lacked consistent formatting
Ambiguous user queries written in everyday language
Relevance ranking, link analysis, and performance optimization became critical. Finding information was no longer just about matching words; it was about delivering the best possible answer first.
Today: AI-Driven Retrieval
Modern systems use advanced techniques such as:
Machine learning, which allows systems to learn from data, improve relevance over time, and adapt based on user interactions.
Natural language processing, which helps systems understand how humans naturally phrase questions, including grammar, intent, and context.
Semantic understanding, which enables systems to recognize meaning and relationships between concepts rather than relying only on exact keyword matches.
These technologies allow systems to move beyond rigid rules and predefined patterns. Instead of relying only on static instructions, modern IR systems continuously learn from data and improve with use.
They don’t just retrieve data; they interpret intent, recognize patterns in behavior, and adjust results based on past interactions.
Over time, this adaptability makes retrieval more accurate and personalized. Thus, information retrieval moves closer to how humans actually search, explore, and think, making the experience feel more intuitive and responsive.
Core Components of an Information Retrieval System
To truly understand what is information retrieval system, you need to know its building blocks. These components work together like parts of a well-orchestrated machine. Each one has a specific role, and if even one piece is weak, the overall quality of retrieval drops noticeably.
1. Document Collection
This is the data source. It is the foundation on which everything else is built. It represents all the information the system can possibly retrieve. The collection may include:
Text documents such as articles, reports, and notes
Web pages from internal or external websites
PDFs, presentations, and manuals
Emails and communication records
Multimedia content like images, audio, and video
The size, diversity, freshness, and accuracy of this collection directly affect retrieval quality. A system trained on outdated or incomplete data will return poor results, no matter how advanced the algorithms are.
2. Indexing Module
Indexing transforms raw data into a searchable structure that machines can understand and access quickly.
Instead of scanning every document each time a user searches, the system creates an index — a shortcut map of important terms, concepts, and their locations across documents. This dramatically reduces response time.
Think of it like a book’s index, but smarter, faster, and constantly updating as new information is added or old information changes.
3. Query Processing
When a user types a query, the system doesn’t take it at face value. Instead, it processes the query to understand what the user actually means.
During this step, the system typically:
Cleans unnecessary words or symbols
Breaks the query into meaningful terms
Expands or refines it using synonyms or related concepts
This step is crucial because humans don’t always ask questions clearly. Queries are often vague, incomplete, or conversational, and the system must bridge that gap.
4. Matching and Ranking
Here’s where the magic really happens.
The system compares the processed query with indexed documents to find possible matches. Then, it ranks those matches based on relevance signals such as term frequency, context, freshness, and sometimes user behavior.
Not all matches are equal. Ranking ensures that the most useful and meaningful results appear first, saving users from scrolling endlessly.
In enterprise-grade systems, ranking often goes beyond keywords. Solutions like Action Sync factor in organizational context, such as project relevance, recency of decisions, team ownership, and workflow state. This way, results align with how work actually happens, not just how documents are written.
5. User Interface
Finally, results must be presented clearly and intuitively. Even the most accurate retrieval system fails if users can’t understand or navigate the output.
A good user interface:
Displays relevance in an obvious way
Allows filtering, sorting, or refining results
Encourages exploration without overwhelming the user
Without this layer, even the best retrieval system struggles to deliver real value.
Taken together, these components explain why information retrieval is not a single action but a coordinated process. Each part supports the next, from collecting raw data to presenting meaningful results. When all components work in harmony, users experience fast, accurate, and intuitive search. When one fails, relevance suffers. Understanding these building blocks makes it clear why strong information retrieval systems feel effortless to use, even though a great deal of complexity is quietly working behind the scenes.
Types of Information Retrieval Systems
Not all IR systems are built the same. Different problems need different approaches, and the way information is searched often depends on the type of data involved and the user’s intent. Some systems prioritize speed, others focus on accuracy, and some are designed to balance both.
Type #1: Text-Based Information Retrieval
This is the most common and widely used form of information retrieval. It focuses on searching and ranking textual content based on keywords, relevance, and context.
Text-based retrieval is commonly used for:
Articles and blog posts
Research papers and academic journals
Reports, documentation, and written records
Because text is relatively easy to index and analyze, these systems form the backbone of most search engines and digital libraries.
Type #2: Multimedia Information Retrieval
Multimedia information retrieval goes beyond text and deals with non-textual content. This includes:
Images
Audio files
Video content
Here, search is often based on metadata, extracted features, patterns, or even visual and audio similarities. Since multimedia data cannot always be searched using simple keywords, these systems rely on advanced techniques to understand content structure and context.
Type #3: Web Information Retrieval
Web information retrieval is designed specifically for the internet’s massive scale and constant change. It must handle a wide range of challenges, such as:
Duplicate or near-duplicate content
Hyperlinks connecting pages
Authority and trust signals
These systems aim to deliver the most relevant and reliable results quickly, even when dealing with billions of web pages and unpredictable user queries.
Type #4: Domain-Specific Retrieval
Domain-specific information retrieval systems are built for specialized fields where precision is critical. They are commonly used in areas such as:
Medicine and healthcare
Law and legal research
Finance and economics
In these domains, accuracy matters more than speed. A single incorrect result can have serious consequences, which is why these systems are carefully tuned to prioritize correctness and reliability over broad coverage.

How Information Retrieval Systems Work? Step by Step Explained
Let’s connect the dots and slow this process down, step by step.
What looks simple on the surface is actually a carefully designed pipeline where each stage builds on the previous one. Every step depends on the accuracy and effectiveness of the step before it. Miss one stage, rush another, or design one poorly, and the entire system starts to wobble. Relevance drops, results feel random, and user trust slowly erodes.
This pipeline exists to balance two difficult goals at the same time: speed and accuracy. The system must work fast enough to feel instant, yet carefully enough to return meaningful results.
Step 1: Documents are collected
The system first gathers data from multiple sources such as websites, files, databases, or internal repositories. This collection can be static, like an archived library, or constantly updated, like live web content. The broader and cleaner the sources, the better the system’s potential performance.
Step 2: Content is cleaned and indexed
Raw data is processed to remove noise such as duplicates, broken text, or irrelevant elements. Important terms, concepts, and relationships are then organized into an index that allows fast searching later. This step prepares the data so it can be retrieved in milliseconds rather than minutes.
Step 3: User submits a query
The journey really begins when a user types a question, keyword, or phrase. Most queries are short, informal, and imperfect, reflecting how humans naturally think rather than how machines prefer to receive instructions.
Step 4: Query is analyzed
The system interprets the query to understand intent rather than taking the words at face value. It handles spelling mistakes, language variations, synonyms, and sometimes even context from previous searches or user behavior. This step ensures the system searches for meaning, not just exact words, which is essential because human queries are often vague, incomplete, or conversational.
Step 5: Documents are matched
Indexed documents are compared against the interpreted query to find potential matches. At this stage, the system evaluates multiple relevance signals, including term usage, contextual alignment, information freshness, and document structure. The goal is to narrow down a large collection into a smaller set of genuinely relevant candidates.
Step 6: Results are ranked
The matched documents are ordered using ranking algorithms so the most useful and trustworthy information appears first. Ranking is critical because users rarely look beyond the top few results, and even a small change in order can significantly affect what information is seen and trusted.
Step 7: Output is displayed
The final results are presented in a clear, usable format that helps the user act quickly, refine their search, or explore further without confusion. Good presentation supports better decision-making by making relevance, clarity, and next steps immediately obvious.
Simple flow on paper. Powerful impact in practice. This carefully sequenced process is what allows information retrieval systems to respond in milliseconds while still handling massive volumes of data and delivering results that actually feel relevant.
Information Retrieval vs Database Systems
This confusion often arises, especially among beginners new to data systems or search technologies. Many people naturally assume that information retrieval systems and database systems work the same way, but in practice, they are built for very different purposes and user needs.
Aspect | Information Retrieval | Database Systems |
|---|---|---|
Query Type | Unstructured | Structured |
Matching | Approximate | Exact |
Ranking | Yes | No |
Flexibility | High | Low |
Databases answer facts by returning precise, structured results. IR systems answer needs by interpreting intent, ranking relevance, and helping users discover information that best fits their situation.
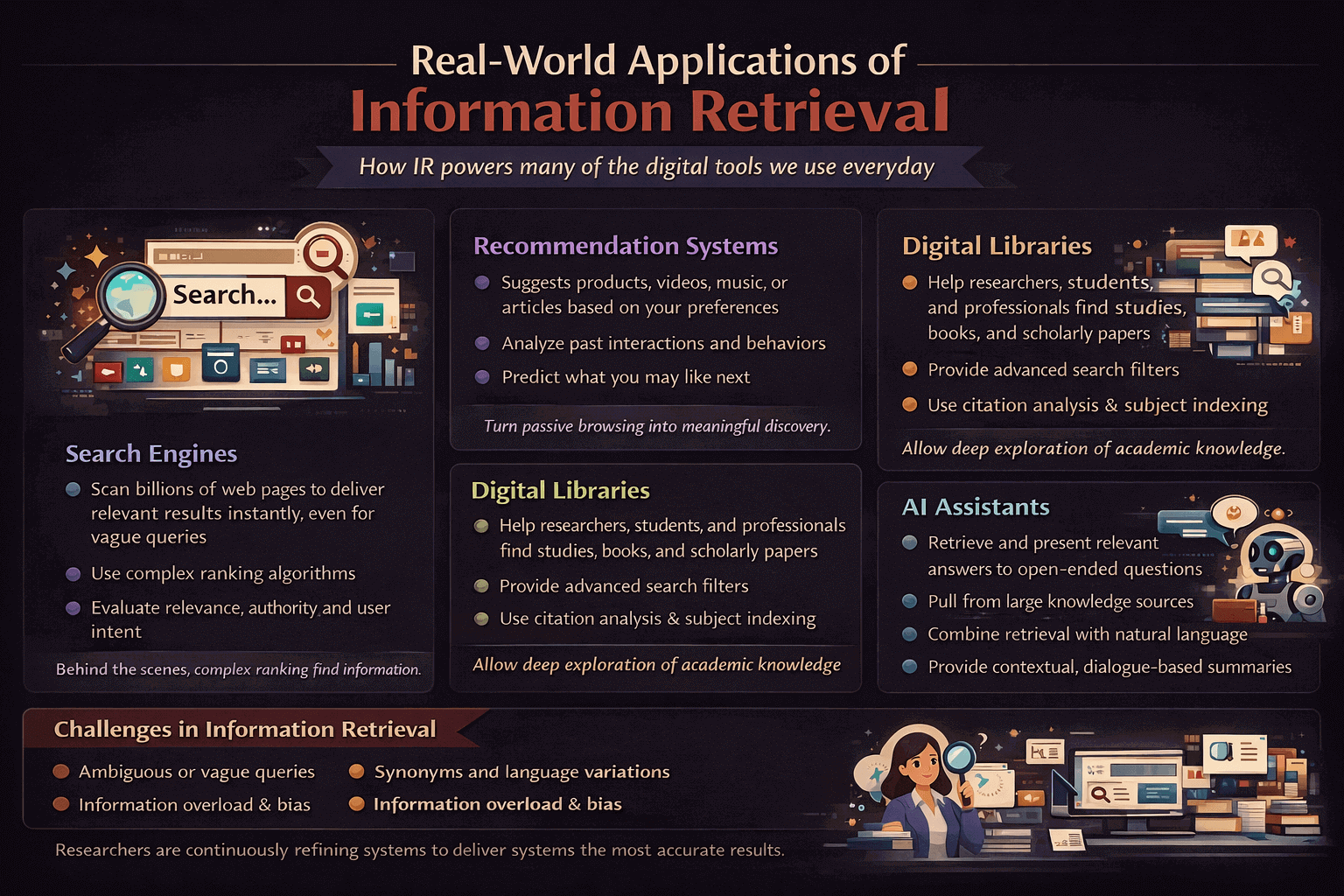
Real-World Applications of Information Retrieval
Information retrieval is everywhere. It quietly supports many of the digital tools people rely on every single day, often without them realizing it. From casual browsing to critical decision-making, IR systems help surface the right information at the right moment.
Search Engines
Search engines are the most familiar example of information retrieval in action. They scan massive collections of web pages and deliver relevant results almost instantly, even when the query is vague or loosely worded. What makes this possible is the system’s ability to process enormous amounts of information at scale while still responding in a fraction of a second.
Behind the scenes, complex ranking algorithms evaluate relevance, authority, freshness, and user intent, combining hundreds of signals to decide which pages deserve visibility. The goal is not just to find matching pages, but to surface results that genuinely answer the user’s question and feel trustworthy.
Recommendation Systems
Recommendation systems use information retrieval techniques to suggest products, videos, music, or articles based on user preferences and behavior. They work by studying what users have viewed, clicked, liked, or ignored over time.
By analyzing past interactions, similar content, and patterns across many users, these systems can predict what a person may find useful next. As a result, they help users discover items they might not actively search for but are still highly likely to find relevant, engaging, or valuable, often turning passive browsing into meaningful discovery.
Digital Libraries
Digital libraries rely on information retrieval to help researchers, students, and professionals locate relevant studies, books, and academic papers without manually scanning thousands of documents. These systems are designed to support deep, focused exploration of knowledge rather than quick surface-level searches.
Advanced search filters, citation analysis, and subject indexing make it easier to explore vast collections of scholarly knowledge efficiently, allowing users to trace research trends, identify influential works, and access credible sources with confidence.
Enterprise Search
Enterprise search systems allow employees to locate internal knowledge such as documents, emails, reports, and policies across large and often fragmented organizational systems. Instead of relying on memory or manual browsing, employees can quickly access the information they need from a single search interface.
Effective retrieval improves productivity by reducing time spent searching, minimizing duplication of effort, and ensuring that critical information is accessible across teams and departments when it is needed most.
AI Assistants
AI assistants depend heavily on information retrieval to retrieve contextual answers in real time, especially when users ask open-ended or conversational questions. They combine retrieval with language understanding to respond to queries, provide summaries, and support everyday tasks such as planning, learning, or decision-making.
By pulling relevant information from large knowledge sources and presenting it in a dialogue format, these systems make access to information feel more natural, interactive, and intuitive, closely mirroring how humans ask questions and seek help.
Information retrieval systems aren’t perfect, and they face several ongoing challenges that make accurate search difficult. Users often submit ambiguous queries that can be interpreted in multiple ways, while synonyms and variations in language add further complexity. At the same time, information overload makes it harder to surface truly relevant results, especially when large volumes of content are available.
Bias in ranking algorithms can influence what information is prioritized, and systems must constantly balance freshness with relevance so that newer content does not automatically overshadow more accurate or authoritative sources. Solving these interconnected challenges keeps researchers and engineers continuously refining information retrieval systems.
Role of AI and Machine Learning in Information Retrieval Systems
Modern information retrieval systems rely heavily on AI, especially as the volume, variety, and complexity of data continue to grow. Thus, making traditional rule-based search methods increasingly ineffective in handling real-world information needs.
They use:
Natural language processing to understand how humans naturally ask questions
Neural embeddings to capture semantic relationships between words and concepts
User behavior analysis to learn from clicks, searches, and interactions over time
Together, these techniques allow systems to understand intent, not just keywords. Instead of treating a query as a simple string of words, the system interprets meaning, context, and purpose, taking into account how language is actually used by real people in real situations. This shift helps systems respond more accurately even when queries are vague, conversational, or imperfect.
It’s no longer about matching words exactly. It’s about matching meaning, relevance, and user expectations, while adapting to different contexts and evolving needs. The result is a search experience that feels less mechanical and more intelligent, human-centered, and aligned with how people naturally think and ask questions.
Evaluation of Information Retrieval Systems
How do we know a system works? Well, evaluating an information retrieval system is essential because good performance is not just about speed, but about delivering genuinely helpful results.
Key metrics include:
Precision, which measures how many retrieved results are actually relevant
Recall, which measures how many relevant results were successfully retrieved
F1-score, which balances precision and recall into a single value
Mean Average Precision, which evaluates ranking quality across multiple queries
Together, these metrics help researchers and engineers understand not just whether the system finds information, but how accurately and consistently it does so.
In simple terms: did the system return useful results, in the right order, when the user needed them?
Future of Information Retrieval
The future looks exciting, especially as information retrieval systems continue to evolve alongside advances in AI and computing power.
Expect:
Conversational search, where users interact naturally using full questions instead of keywords
Multimodal retrieval, combining text, images, audio, and video in a single search experience
Personalized results, tailored to individual preferences, behavior, and context
Real-time context awareness, where systems adapt responses based on location, intent, and timing
Together, these trends signal a major shift. Information retrieval is moving from simple search to deeper understanding, where systems don’t just return results, but actively help users interpret, explore, and apply information more effectively.

FAQs or Frequently Asked Questions
Q: Is Google an information retrieval system?
Yes, Google is one of the most advanced examples of an information retrieval system.
Q: How is information retrieval different from data retrieval?
In information retrieval, the system’s goal is to understand what the user actually needs, even if the query is vague, incomplete, or phrased in natural language. Instead of returning everything that technically matches the query, it evaluates context, meaning, and usefulness, then ranks results by relevance, surfacing the most helpful information first.
Data retrieval, on the other hand, is built for precision and structure. It works with well-defined queries over structured data, where the expectation is a specific, exact result. If the query conditions are not met exactly, the system simply returns nothing, regardless of intent or usefulness.
In short, data retrieval answers facts, while information retrieval answers needs. One prioritizes correctness and certainty; the other prioritizes relevance, interpretation, and discovery.
Q: Why are information retrieval systems important?
They help manage information overload by filtering out noise and surfacing only what is relevant at the moment of need. Instead of forcing users to sift through endless documents, messages, and data sources, information retrieval systems prioritize context, relevance, and intent. This enables people to spend less time searching and more time thinking, leading to faster, more confident, and better-informed decisions.
Q: What are common examples of information retrieval systems?
Common examples include search engines, digital libraries, email search tools, recommendation systems, enterprise search platforms, and enterprise AI assistants that retrieve information based on user queries.
Q: What type of data does an information retrieval system handle?
Information retrieval systems mainly handle unstructured or semi-structured data such as text documents, web pages, emails, images, audio, and videos.
Q: How does an information retrieval system rank results?
It ranks results using relevance signals like keyword importance, context, freshness, document structure, and sometimes user behavior, ensuring the most useful information appears first.
Q: What is the difference between information retrieval and web search?
Web search is a specific application of information retrieval, while information retrieval is a broader concept that applies to many domains beyond the internet.
Q: Can information retrieval systems work without AI?
Yes, traditional systems can work without AI, but modern information retrieval systems rely on AI to better understand intent, language, and context.
Q: What challenges do information retrieval systems face?
Information retrieval systems face challenges such as ambiguous and poorly defined queries, variations in language and expression, and overwhelming volumes of data that can bury relevant information. They must also manage ranking bias, where certain results are unintentionally favored, and strike a careful balance between freshness and relevance so that timely content does not override accuracy or reliability.
Q: How is information retrieval used in artificial intelligence?
In artificial intelligence systems, information retrieval plays a foundational role by supplying the right knowledge at the right moment. Instead of relying solely on what a model has been trained on, AI systems actively retrieve relevant documents, facts, and contextual signals from large knowledge sources to support tasks such as question answering, content summarization, personalized recommendations, and conversational interactions.
This retrieval step ensures that AI responses are grounded in real, up-to-date information rather than guesses or generic patterns. By pulling in the most relevant context before generating an output, AI systems can produce answers that are more accurate, specific, and aligned with user intent. In practice, information retrieval acts as the bridge between static knowledge and dynamic reasoning, enabling AI to move beyond language generation and function as a reliable, context-aware assistant.
Conclusion
So, what is an information retrieval system after all? It’s the silent engine behind modern knowledge discovery, quietly working in the background every time we search, explore, or try to understand something new. It’s what helps us make sense of endless data by turning scattered information into clear, usable insight. And frankly, without it, the digital world as we know it would slow down, if not grind to a complete halt.
Understanding the information retrieval system meaning isn’t just for engineers or researchers building complex systems. It’s for anyone who searches the web, learns a new skill, makes decisions, or creates content in today’s information-driven world. Whether you realize it or not, you interact with information retrieval systems dozens of times every day.
From libraries to enterprise assistant software, IR systems shape how we access truth, insight, and opportunity across education, business, healthcare, and everyday life. And as technology continues to evolve, their role will only grow stronger, more intelligent, and more deeply integrated into how we think and work.
As organizations grow more complex, information retrieval is increasingly embedded into daily work itself. Tools like Action Sync reflect this shift, where retrieval, context, and action converge to help teams think less about searching and more about executing.
In a noisy world filled with endless data, information retrieval systems don’t just find answers. They find meaning, helping people move from confusion to clarity.


