Back
Enterprise
Difference Between Information Retrieval and Data Retrieval

Tushar Dublish

Let’s be honest. The difference between information retrieval and data retrieval sounds like one of those textbook phrases you’d expect to skim past without a second thought, right? Dry. Academic. Easy to ignore. But here’s the twist: once you truly understand what it means, you start seeing modern technology through a completely different lens. Search engines, databases, AI systems, dashboards, CRMs, you name it. Almost everything you touch daily relies, in one way or another. On either information retrieval or data retrieval, it quietly works in the background.
Yet people mix them up. All the time. In meetings. In documentation. Even in product discussions.
Someone casually says, “We’re retrieving data,” but what they really mean is that they’re trying to ‘find meaning’ in scattered content. Another person proudly claims, “We built an information system,” when, in reality, the system is just pulling rows from a database with zero interpretation involved. Confusing? Absolutely. Costly when misunderstood? You bet. Important? Even more so.
That’s exactly why this article exists. It clears the fog. Slowly. Clearly. Practically. No rushing. No assumptions.
We’ll explore the difference between information retrieval and data retrieval, unpack information retrieval vs data retrieval, and compare the two. There’s no jargon overload here. No robotic explanations.
By the end, you won’t just know the difference. You won’t just memorize definitions. You’ll feel it, understand it, and spot it everywhere you look.
What is Data Retrieval? Explained Simply.
Let’s start with the simpler sibling, the one that prefers clarity over creativity and certainty over guesswork.
Data retrieval is the process of fetching exact data from a structured source (usually a database) based on a precise, well-defined query. You ask for something specific, in a format the system clearly understands. The system responds by giving you exactly that, nothing more and nothing less. No interpretation. No assumptions. No guessing is involved at any stage.
In data retrieval, the rules are strict and predictable. If the data exists and your query is correct, you get a result. If it doesn’t exist or the query is flawed, you get nothing. Simple as that.
Think of it like pulling a clearly labeled file from a well-organized cabinet. You know the drawer. You see the folder. You open it, take out the document, and move on. No surprises.
Key Characteristics of Data Retrieval
Before diving into the specific traits, it helps to pause and understand what truly defines data retrieval at its core. This section breaks down the fundamental qualities that make data retrieval predictable, reliable, and well-suited for systems where precision matters more than interpretation.
Works with structured data (tables, rows, columns), where every field follows a fixed schema and predefined rules
Uses exact queries (SQL, filters, IDs) that must match the data format precisely to return results
Returns raw facts, not explanations, summaries, or interpretations of what the data might mean
Focuses on accuracy and speed, often optimized for performance, scale, and reliability
Minimal ambiguity, because every request and response follows strict logic with little room for interpretation
A Simple Example:
You run this query:
“Get all orders placed on 12 June 2025.”
The database doesn’t pause to wonder why you want this information or what you plan to do with it next. It doesn’t try to summarize trends, identify patterns, or provide insights about customer behavior. Instead, it follows the instruction exactly as written and scans its tables for records that match the given date.
Once the matching entries are found, it simply returns those rows as they are. All in clean, precise, and unfiltered format. No extra context. No interpretation layered on top.
That’s data retrieval in action, straightforward and predictable. In most enterprise setups, this kind of data retrieval happens constantly in the background. Enterprise search tools like Action Sync don’t replace these systems. Instead, they build on top of them, relying on accurate data retrieval as a foundation before any higher-level interpretation begins.
Where Data Retrieval Shines?
Data retrieval proves its true value in environments where correctness, consistency, and trust in numbers are critical. These are situations where even a small mismatch can lead to financial loss, compliance issues, or operational failures.
Below are some common areas where data retrieval is not just useful, but essential.
Banking transactions, where accuracy and traceability are non-negotiable
Inventory management systems that track stock levels, SKUs, and availability in real time
Payroll systems responsible for salaries, taxes, deductions, and compliance
User account records storing profiles, credentials, and access permissions
Analytics dashboards that rely on clean, structured inputs to generate reports
In short, when precision, consistency, and reliability are the top priorities, data retrieval clearly wears the crown.

What is Information Retrieval? Explained Simply.
Now things get interesting.
Information retrieval is about finding relevant information, not exact data. Unlike rigid systems that expect perfectly formed inputs, information retrieval systems are designed to understand what a user is really trying to find. They interpret intent, weigh relevance, and consider context before presenting results.
They don’t panic when queries are vague or incomplete. Instead, they deal with uncertainty. And, in fact, embrace it as part of the process.
Rather than demanding precision, these systems work by estimating usefulness. They scan large collections of content, evaluate meaning, and decide what is most likely to help the user. Sometimes they get it perfectly right. Other times, they get close enough to guide you in the right direction.
Instead of pulling a file from a cabinet, you’re essentially asking someone to explain where to look, what might matter, and which paths are worth exploring first.
Key Characteristics of Information Retrieval
This section highlights the core characteristics that enable information retrieval systems to handle uncertainty, interpret human intent, and surface meaning rather than merely matching exact values. Here are a few key features you can account for,
Works with unstructured or semi-structured data, such as articles, documents, emails, web pages, and mixed-content sources
Handles natural language queries, allowing users to search the way they think and speak, not the way systems are structured
Focuses on relevance, not perfection, aiming to surface the most useful results rather than exact matches
Often ranks results by usefulness, confidence, or context, instead of returning a single fixed answer
Accepts ambiguity as a feature, not a flaw, and is designed to work even when queries are incomplete or loosely defined
A Simple Example:
When you search:
“Best laptops for video editing under $2000”
The system doesn’t fetch a single row from a table or look for an exact match stored somewhere. Instead, it scans thousands of articles, expert reviews, buying guides, comparison pages, and user opinions spread across the web. It evaluates which sources seem trustworthy, which ones are recent, and which ones best align with what you might be looking for.
It then ranks the results based on relevance, popularity, and context. Along the way, it makes educated guesses about your intent. Are you a professional editor, a student, or a casual creator? And then tries its best to surface content that will genuinely help you make a decision.
This is the exact layer where enterprise-focused systems like Action Sync operate. Rather than just pulling records, they help teams search across internal tools, documents, and conversations to surface information that is contextually relevant to what someone is trying to accomplish.
Where Information Retrieval Shines?
Information retrieval truly stands out in situations where users are searching for understanding, ideas, or guidance rather than exact values. These are environments where questions are open-ended, data is messy or text-heavy, and relevance matters more than precision.
Below are some common areas where information retrieval delivers the most value.
Search engines that help users discover answers, ideas, and resources across massive collections of web content
Document search systems used inside organizations to locate reports, policies, research papers, and internal knowledge
Email search tools that scan conversations, attachments, and threads to surface relevant messages quickly
Recommendation engines that suggest products, videos, articles, or music based on user behavior and context
AI-powered assistants that interpret questions, understand intent, and respond with meaningful, conversational answers
If meaning, context, and usefulness matter more than raw precision, information retrieval clearly takes the lead. By relying on information retrieval, users can discover insights, explore possibilities, and arrive at answers that feel genuinely helpful rather than mechanically correct.
Difference Between Information Retrieval and Data Retrieval (Table)
Before we go deeper, here’s a quick snapshot.
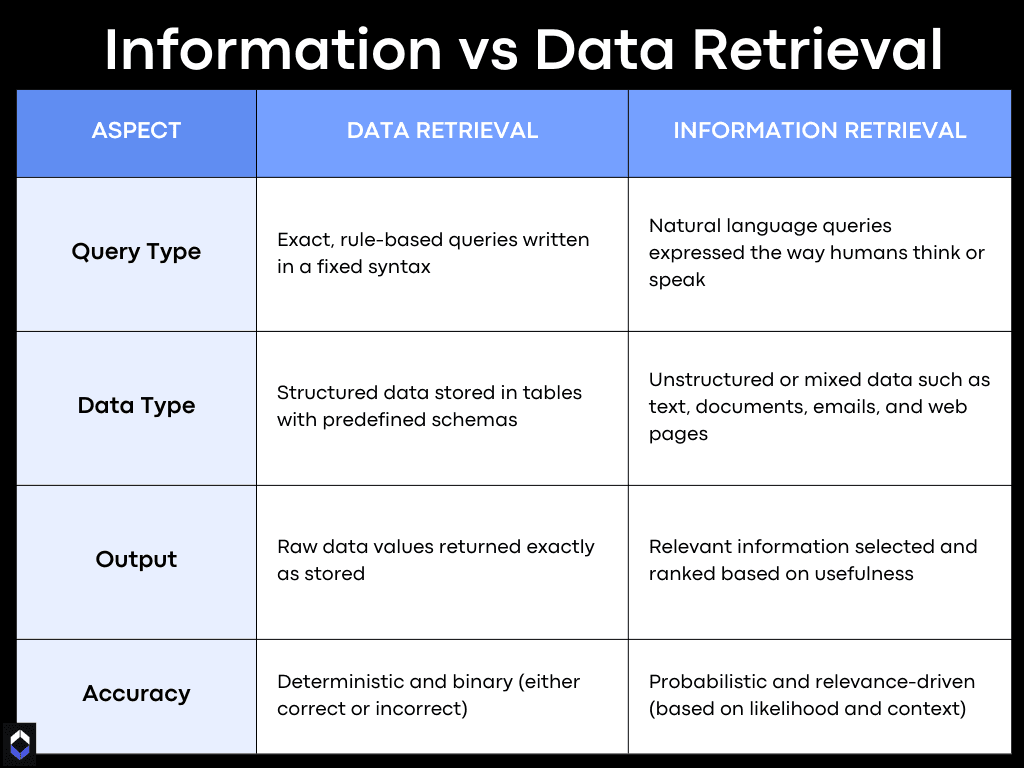
Simple? Yes. Complete? Not yet.
Let’s dig further.
Round-Wise Comparison: Information Retrieval vs Data Retrieval
Now comes the heart of this article. A round-wise comparison that makes the difference between information retrieval and data retrieval crystal clear.
Round 1: Nature of the Query
Data Retrieval:
In data retrieval, queries are formal and structured by design. The system expects inputs to follow a strict syntax and predefined rules, leaving little room for flexibility or interpretation. Every query must clearly specify the fields, tables, and conditions it wants to access, otherwise the system fails to return results.
Key points to remember:
Queries rely on predefined fields, schemas, and formats
The structure of the query matters as much as the data itself
Example:
SELECT name FROM users WHERE id = 102
Information Retrieval:
Here, queries are informal and human by nature. Users are not expected to know exact fields, table names, or strict syntax. Instead, they express what they are looking for in natural language, often in the form of questions or rough descriptions. These queries may be vague, incomplete, or loosely phrased, yet the system still attempts to interpret intent and return meaningful results.
Key points to remember:
Queries are conversational and human-friendly
They can be vague, broad, or incomplete
Example: “Users who recently signed up?”
Winner: Information Retrieval (for flexibility)
Round 2: Type of Data Handled
Data Retrieval:
It works exclusively with structured data that follows a strict and predictable organization. The data is stored in clearly defined tables, governed by fixed schemas, and enforced by constraints that maintain accuracy and consistency. Because everything is predefined, the system knows exactly how to locate and return values without needing to interpret meaning or intent.
Key points to remember:
Data is strictly structured and schema-driven
Information is stored in tables with defined fields and relationships
Constraints ensure consistency, validity, and reliability
Information Retrieval:
Here, unstructured data plays a dominant role. Unlike neatly organized tables or fixed schemas, this type of data exists in free-form formats where meaning is embedded in language, context, and presentation. As a result, the system must analyze and interpret the content itself to determine relevance rather than relying on predefined fields.
Key points to remember:
Most of the data is unstructured or loosely structured
Common formats include text documents, PDFs, emails, and web pages
Meaning is derived from content and context, not fixed schemas
Winner: Information Retrieval (for real-world content)
Round 3: Precision vs Relevance
Data Retrieval:
The precision is absolute and non-negotiable. Every query is evaluated against strict rules and predefined conditions, which means the outcome is always binary. A record either satisfies the query perfectly or it does not exist in the result set at all. There is no room for approximation, ranking, or interpretation.
Key points to remember:
Results are strictly exact and rule-based
Records either match the query conditions or are excluded entirely
There is no concept of partial matches or relevance scoring
Information Retrieval:
Relevance is subjective rather than absolute. The system does not decide results using a strict yes-or-no condition. Instead, it evaluates how useful each piece of information might be for a given query and orders the results based on that judgment. What appears at the top is what the system believes is most helpful in context, not necessarily what is perfectly correct.
Key points to remember:
Relevance depends on user intent, context, and interpretation
Results are ranked instead of strictly filtered
Multiple results can be useful, even without exact matches
Winner: Depends on your goal.
Round 4: Handling Ambiguity
Data Retrieval:
Here, ambiguity is not tolerated. The system expects inputs to be clear, precise, and fully aligned with predefined rules and formats. When a query is vague, incomplete, or incorrectly structured, the system does not attempt to infer intent or guess meaning. Instead, it stops processing immediately and either returns no result or throws an error.
Key points to remember:
Ambiguous or unclear inputs are not accepted
Queries must be precise and correctly structured
The system fails fast rather than making assumptions
Information Retrieval:
The systems are intentionally designed to handle ambiguity rather than reject it. They assume that user queries may be unclear, incomplete, or open to multiple interpretations. Instead of failing when inputs are imperfect, these systems apply intelligent techniques to estimate relevance and deliver the most useful results.
Key points to remember:
Ambiguity is expected and handled gracefully
Scoring and ranking mechanisms determine result order
Heuristics help infer user intent and relevance
Winner: Information Retrieval

Round 5: User Experience
Data Retrieval:
The experience is largely developer-centric. These systems are built primarily for engineers and technical teams, where the focus is on writing precise queries, managing schemas, and ensuring efficient backend operations. Most of the complexity stays behind the scenes, with little emphasis on end-user interaction.
Key points to remember:
Designed mainly for developers and technical users
Strongly focused on backend logic and infrastructure
Limited direct interaction for non-technical users
Information Retrieval:
The overall experience is user-centric by design. These systems are created with end users in mind, focusing on ease of use, clarity, and intuitive interaction. Rather than exposing technical complexity, they emphasize frontend experiences that make searching, browsing, and discovering information feel natural and effortless.
Key points to remember:
Designed primarily for end users, not developers
Strong focus on frontend-friendly and intuitive interfaces
Prioritizes usability, accessibility, and smooth interaction
Winner: Information Retrieval
Round 6: Speed and Performance
Data Retrieval:
These are designed to be extremely fast. They are optimized to return results in milliseconds by relying on predictable query patterns and efficient storage mechanisms. Performance is a core requirement, especially in systems that handle large volumes of transactions or real-time requests.
Key points to remember:
Optimized indexes help locate data quickly
Queries require minimal computation or interpretation
Speed remains consistent even at scale
Information Retrieval:
Performance is generally slower because the system does more than simply return results. Before responding, it analyzes large volumes of content, evaluates relevance, applies ranking algorithms, and sometimes interprets user intent. This additional processing takes time, but it ensures that the results are meaningful and context-aware rather than just fast.
Key points to remember:
Extra time is spent on ranking, scoring, and relevance analysis
Results are optimized for usefulness, not just speed
Slower responses trade raw performance for better context and quality
Winner: Data Retrieval
Round 7: Typical Tools and Systems
Data Retrieval Tools: SQL databases, NoSQL stores, APIs, etc.
Information Retrieval Tools: Search engines, Indexing systems, AI-based retrieval models, etc.
Winner: Tie (different jobs, different tools)
Why People Confuse Data Retrieval vs Information Retrieval?
Honestly? Because modern systems blur the line more than ever before. As technology becomes smarter and more user-friendly, the underlying complexity is intentionally hidden from view.
Users experience a simple interface, but behind the scenes, multiple retrieval mechanisms often work together.
Search bars hide complexity by presenting a single input box while triggering different retrieval processes underneath
AI systems combine both approaches, often retrieving exact data first and then applying relevance and interpretation layers
Marketing uses terms loosely, frequently using “data” and “information” interchangeably to keep messaging simple
But under the hood, the difference between information retrieval and data retrieval still matters a lot. It influences system design, performance, scalability, and how accurately technology serves real user needs.
FAQs or Frequently Asked Questions
Q: What is the main difference between information retrieval and data retrieval?
The main difference lies in intent. Data retrieval fetches exact data, while information retrieval finds relevant information based on meaning and context.
Q: Is Google Search an example of information retrieval?
Yes. Google Search is a classic information retrieval system because it ranks and interprets relevance.
Q: Can Systems Use Both?
Absolutely. In fact, the best systems do — and they do so deliberately by combining the strengths of both approaches instead of relying on just one. Rather than treating data retrieval and information retrieval as separate choices, modern platforms use them together in a layered way.
Modern platforms often follow a structured flow:
Retrieve data first to ensure accuracy, consistency, and access to reliable raw facts
Then apply information retrieval layers to interpret relevance, context, and user intent
Finally present insights in a form that is meaningful, actionable, and easy to understand
This hybrid approach is everywhere. Right from enterprise AI assistants like Action Sync that answer complex questions to dashboards that turn raw metrics into insights. By blending both methods, systems achieve precision where it’s required and interpretation where it truly matters.
Q: Is SQL used for information retrieval?
No. SQL is primarily used for data retrieval from structured databases.
Q: Can information retrieval systems use databases?
Yes, but they add interpretation, ranking, and context on top of raw data retrieval.
Q: Which is more important, information retrieval vs data retrieval?
Neither is more important universally. The choice depends on the problem being solved.
Conclusion
So, what’s the real takeaway? The difference between information retrieval and data retrieval isn’t academic fluff or theory meant only for textbooks. It’s a practical, real-world distinction that directly shapes how modern systems are designed, how users interact with technology, and how organizations make decisions at scale.
Data retrieval gives you facts. All clean, precise, and dependable. Information retrieval takes those facts and adds meaning, context, and insight, helping humans actually understand and use what they find.
One is exact and rule-driven. The other is interpretive and insight-driven. Each serves a different purpose, and neither can replace the other in today’s digital ecosystem.
And together? They quietly power the digital world we rely on every single day. Right from search engines and dashboards to AI assistants and enterprise platforms.
This is also why modern enterprise assistant tools, including platforms like Action Sync, focus less on just “search” and more on helping people move from information to action. Because finding something is only half the problem. Knowing what to do with it is the real challenge. Want to know more? Book a free demo to explore possibilities.
Once you truly see the difference, you can’t unsee it. And honestly, that deeper understanding is a powerful thing.


